爬虫案例比较,爬虫案例比较,爬虫案例比较,爬虫案例比较爬虫案例比较
”爬虫 信息比较“ 的搜索结果
python爬虫爬取企业详细信息,并保存到mysql数据库,包含代理IP的使用。
1、python爬取企查查公司信息 2、添加应对反爬的设置 3、开箱即用,有示例数据文件 4、windows版本 5、需要登录或者人工验证 6、采用selenium模块+chromedriver驱动
爬取企查查网站上公司的工商信息,路径大家根据自己情况自行修改,然后再在工程路径下创建个company.txt,里面输入想要爬取的公司名,就会生成该公司的工商信息网页。
多年爬虫领域老工程师深度总结反爬虫技术原理与场景,带你快速了解并掌握反爬虫技术栈知识
模板爬虫的主要优势在于简化了爬虫的开发过程!降低了技术门槛,提高了爬虫的可维护性和灵活性


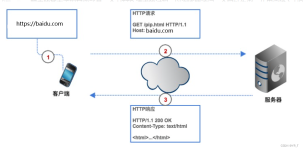
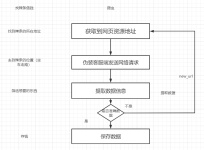

在本文中,我们学习了如何使用代理服务器来爬取天气预报信息。在实际使用过程中,我们需要注意代理服务器的稳定性和可用性。建议在使用代理服务器时,选择可靠的代理服务器,以确保我们的程序正常工作。此外,我们还...
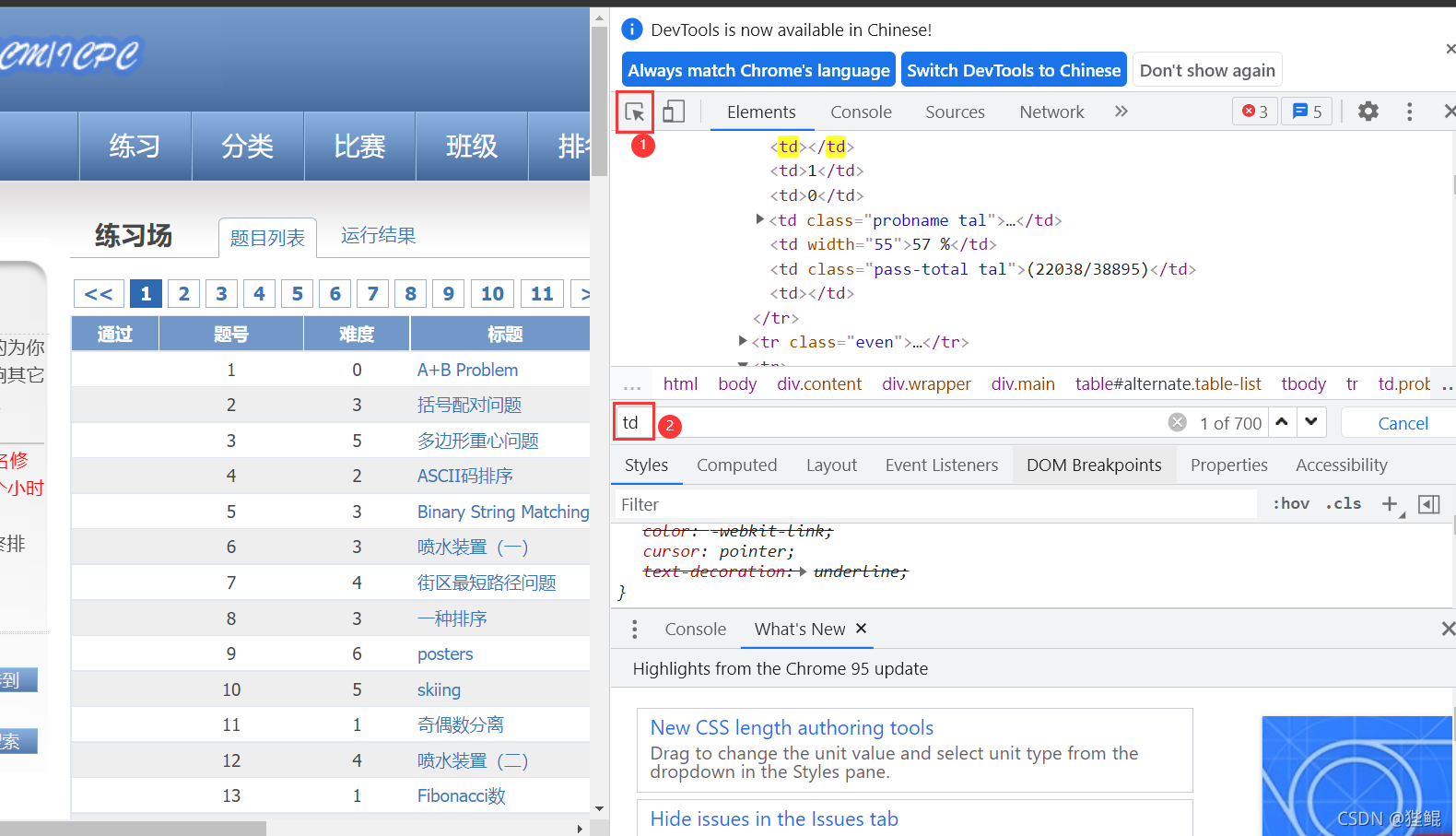


爬取目标:通过东方财富网获取股票列表,借此构造链接从富途牛牛网获取个股信息并保存到本地列表中;相关库名:requests/re/json/csv
国家企业信用信息公示系统及30多个省份的子系统均采用了加速乐的反扒,仔细研究可发现其主要的5个cookie(__jsluid_h, __jsl_clearance, JSESSIONID, SECTOKEN, tlb_cookie)是多次请求结果运算得出的。...
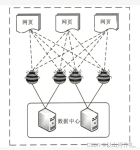

接下来我将通过三篇文章介绍如何通过天气网 (weather.com.cn)爬取天气信息。本文将介绍爬取地区名称与地区ID的对应关系,为爬取天气信息打下基础。

一个优秀的爬虫采集系统,它的告警功能一定会这样去考虑与设计

根据网络上的定义,网络爬虫为使用任何技术手段批量获取网站信息的一种方式。“反爬虫”就是使用任何技术手段阻止批量获取网站信息的一种方式。01、为什么会被反爬虫对于一个经常使用爬虫程序获取网页数据的人来说,...
所以,你知道爬虫的作用了吗?


经常有小伙伴需要将互联网上的数据保存的本地,而又不想自己一篇一篇的复制,我们第一个想到的就是爬虫,爬虫可以说是组成了我们精彩的互联网世界。 网络搜索引擎和其他一些网站使用网络爬虫或蜘蛛软件来更新他们的...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地